Start with a piece of design history the reader already half knows, because the shape of this chapter depends on seeing it whole.
The web captured eyeballs. In the first era of the commercial internet, the operative unit was the eye on the page. Sites were built to be looked at, and the metric was the pageview, the impression, the unique visitor. The business model was advertising sold against impressions. Design vocabulary grew up around the viewer — stickiness, information architecture, navigation, time on site.
Social media captured attention. The unit shifted from the eye to the attentional act. Engagement metrics measured attention at a finer granularity: dwell time, scroll depth, likes, shares, return rate, session frequency. Variable rewards, notifications, the infinite feed. The business model became advertising sold against precisely measured attention.
Search tried to match output to input. Running through both eras was the effort to match what you were looking for to what was on the shelf. The operative metric was relevance — Google’s PageRank, Amazon’s collaborative filtering, Netflix’s recommendation engine. All different engineering answers to the same design question: given what you typed or clicked, which of the items we already have is most worth showing you? Relevance was a real achievement. It turned an unreadably large index into something a person could use. But it was also a property of an output picked from a list — static, extractive.
AI can engage the mind. The unit shifts again. It is no longer the eye, the attentional moment, or the ranked item. It is your active thinking — the question you are forming, the interest you are pursuing, the topic you are trying to understand, the half-thought you are still trying to find words for. What AI can do that no prior medium could is engage with what you are thinking — go somewhere with it, turn by turn, in a way that moves you further along.
One compressed line for the rest of the chapter:
The web captured eyeballs and its metric was pageviews. Social media captured attention and its metric was engagement. Search matched output to input and its metric was relevance. AI can engage the mind, and its metric is interestingness.
Each era’s goal was the highest the technology could serve and the easiest to measure, and each became its own pathology — banner blindness for eyeballs, the doom scroll for attention, filter bubbles for relevance. We will not pretend interestingness will be different. We will name its pathology before the chapter closes. But we will not pretend the target is the same as the last one.
Interestingness is the design goal proper to AI.
A property of conversation, not of a response. It lives in the shape of the exchange over time — whether the system surfaces what you are actually after, deepens when depth is what the moment calls for, slows down when you need a pause, catches the question you did not quite ask, pivots when the pivot is what interest wants. None of these can be measured in a single response. All of them are things a well-designed conversation can do and a badly designed one cannot.
This is what the earlier chapters were pointing at. We established that AI generates without communicating — and the central gap has appeared and reappeared ever since. We established that AI is structurally passive, and that a well-shaped empty exchange is not, on its own, interesting. We covered content as form and said the topic layer would come later — this is later. We covered the envelope and said it is a precondition, not the goal — the goal is the interesting exchange the envelope makes possible.
What follows is the affirmative version of what the diagnostic chapters were diagnosing. Where they said here is what design has to compensate for, this says here is what design makes possible when it compensates well.
A search engine returns a list ranked by relevance. A recommender returns items ranked by how likely you are to click. Both are relevance machines: given an input, what in the existing collection matches best?
Relevance is a real achievement, and the chapter is not against it — it is an upgrade of it. The move from relevance to interestingness is from static to temporal, from extractive to generative, from picking to pursuing. Relevance returns one of the items we already have. Interestingness makes topical moves in a conversation that is still being built.
Consider a recommender asked what movie you should watch tonight. It predicts the next item you are likely to click on, and it will be good at this. But notice what it is not doing: not asking why you are looking, not noticing that your recent consumption has a pattern worth following, not catching that the last four things you watched were all from the late nineties and there might be something in that. It is not noticing the journey — only the next step along a path it assumes you are already committed to.
Research on persistent user interest journeys1 quantifies the gap. When asked what they are actually doing on a platform, users describe journeys — “designing hydroponic systems for small spaces,” “learning the ukulele as a beginner.” In survey data, most respondents reported pursuing a valued journey, the majority lasting months, many more than a year.1a The semantic gap between “what item would you click on next” and “what journey are you on” is not bridged by better embeddings. And when LLMs are used directly as conversational recommenders, the artificial hivemind effect2 shows up: the most popular items in the training distribution surface again and again regardless of context. The Shawshank Redemption appears in recommendation outputs around 5% of the time across different datasets, reflecting pretraining-corpus popularity, not your context. The capability for journey-awareness exists in the underlying models; the design intention to use it does not.
The Types of Interest taxonomy names the territory from the user side: “the one” (best, expert-picked, ethically-picked), “the best for me” (matching my style, my constraints), “I don’t know what I want” (am I right? are others thinking the same?), “I want to know more” (catch up, deepen, feel secure), “I want to anticipate” (forecasts, risks, defensive moves). Each type calls for a different conversational shape. A recommender cannot distinguish between them because relevance does not distinguish between them. Interestingness can and must.
The ML research gives us the gap in numbers; the design literature gives us the gap in vocabulary. The user’s real target is a trajectory, the trajectory has a type, and the conversational moves that serve it are structurally different from the moves that match an item to a query. A recommender, however exquisitely good at returning the next click, cannot become an interestingness system by being slightly better. Interestingness is a different job.
Abstract claims about interestingness will not survive long without something concrete. Each type of interest below is a named conversational situation — a direction you might be moving in, calling for a different conversational shape.
“The one.” You want a single best answer and are willing to let someone else’s judgment define best. The conversational shape is trust calibration: whose ranking is this, how recent, what criteria, can you trust the recommender to understand your situation?
“The best for me.” You are not looking for the objectively best but for the thing that matches your situation — your style, your constraints, your history. The shape is calibration to you, and the AI cannot serve it without asking the right questions.
“I don’t know what I want.” You are in an anomalous state of knowledge — you know your knowledge is incomplete but cannot specify what is missing. The shape is co-formation of the question: slowing down, offering possibilities, asking the kind of questions that help you discover the shape of your own interest before the system tries to resolve it. This is the type of interest the gulf-of-envisioning3 research is pointing at, and it is the one most current AI products are worst at.
“I want to know more.” You have an established interest and want to go deeper — catch up, feel secure in your understanding, learn the commonly accepted view or the contrarian one. The shape is deepening, and the AI has to respect the pace and know when to hand off to a source you can read on your own.
“I want to anticipate.” You are trying to see around a corner. The shape is forecasting with calibration — willingness to say what the AI thinks will happen while distinguishing the high-confidence parts from the low-confidence parts.
The taxonomy is not the point. The point is that interest has types, that each type calls for a different shape, and that a design discipline organized around interestingness has to start with the question: what kind of interest is this one?
Earlier, we named a distinction we can now use. Content has two layers: form (verification, provenance, legibility) and topic (what the conversation is about, how topics emerge and shift). Chapter 7 was about form. This chapter is about topic, because topic is where interestingness is made.
Topicality is bilateral, and this is the part current AI has the most trouble with. You drift — arriving with a half-formed question, each partial answer exposing adjacent gaps, attention pulled sideways. A topical collaborator would catch this and say wait, are we still on the thing you came in with, or are we somewhere else now? A small conversational move, and current AI almost never makes it.
Three lines converge. CantTalkAboutThis4 tests whether LLMs maintain topical focus against distractor turns — even GPT-4-Turbo engages with distractors, and fine-tuning on a modest set of synthetic dialogues4 significantly improves resilience, meaning the capability is easy to acquire but absent from training. Research on dialogue topic management going back to Grosz and Sidner (1986)5 shows that handling topical re-entry — returning to a topic dropped several turns ago — requires flexible access rather than rigid stacks. And TRACE6 (conversational geometry) finds that a reward model trained on structural features alone — inefficiency, temporal dynamics, semantic cohesion, goal orientation — reaches nearly the same pairwise accuracy on dialogue satisfaction as full-text analysis.6a How a conversation moves through topic space predicts its success almost as well as what it says.
The heuristics framework carries the topicality vocabulary: topicality (staying on topic, managing transitions), depth (matching the desired level of detail), traversing (navigating across topics and following your train of thought), and suggestion (offering the adjacent topic, the next question). These name the design targets the research is measuring the absence of. A system scored against all four would look very different from the chat windows we currently ship — catching your drift, suggesting the adjacent, deepening when depth is called for, navigating back to a topic left dangling three turns ago because it was still your real interest.
The ML research measures topicality as a capability; the design vocabulary treats it as a design surface. Together they turn topicality from a soft concern into something concrete — a dimension that can be measured, scored, trained toward, and designed for. The research exists; the industrial practice does not. The gap is closeable by a design team that decides topicality is what they are building for.
A conversation that lands on the right topic in the wrong register is not interesting — it is uncomfortable.
So far we have been careful about affect. Emotions-as-state-of-mind belong with the user, synchrony belongs with the interaction, performed empathy belongs with the AI itself. What belongs here is narrower: sentiment is the affective coloring of topical content, the register in which the topical move lands.
Three findings. First: emotional rebound7 — negative prompts rarely yield negative answers, rebounding mostly to neutral or positive;7a a tone floor prevents downward shifts; alignment constraints suppress the effect on politically sensitive topics but not everyday ones. The same question produces different information depending on how you feel when you ask it. Second: the INSPIRED dataset8 of 1,001 human-human recommendation dialogues shows that sociable strategies — personal opinion, encouragement, experience inquiry — “more frequently lead to successful recommendations” than information delivery alone. Third: RLVER9 demonstrates that a verifiable emotion score can serve as an RL reward signal, shifting model behavior from solution-centric to genuinely empathic in social-cognition space.
The design vocabulary names the moves: Adaptive Conversational Tempo (the system slows when the conversation needs slowing), Tone Mirror and Match (picking up your register rather than substituting its own), Emotional Authenticity Calibration (distinguishing situations where warmth is appropriate from those where it would be condescending). The heuristics framework names social content as a heuristic in its own right: does the system handle the social and emotional dimensions of an exchange appropriately?
Current models tilt the affective register automatically and invisibly — up when you are negative, down never, locked on sensitive topics, flexible elsewhere. The design vocabulary shows what a deliberate affective register would look like. Sentiment cannot be left to the model, because the model has been trained to rebound toward an average register that serves no specific topical move well. It has to be treated as a design decision — the interface carrying the register through pacing, acknowledgment, and style-matching, or the model trained against a verifiable emotion signal that tracks whether the move actually lands.
Four moves carry most of the shape.
Leading when leading is what the moment calls for. An AI serving interestingness has to be able to say before I answer that, let me ask you something, or the question you are asking is not quite the question you want answered. Proactive critical thinking goes from near-zero to nearly all responses under specific training10a — the capability exists; the training just doesn’t elicit it.
Slowing down when slowness is what the moment calls for. Research on clarifying questions10 shows that questions seeking specific missing information yield higher satisfaction than those rephrasing your needs. A “can you be more specific?” wastes patience; a “are you looking for the 4K monitor for gaming or the color-accurate one for design?” demonstrates understanding.
Pivoting when the pivot is what the moment calls for. Flexible topic management — the return to an earlier topic with its old context intact, the ability to say fifteen minutes ago you mentioned thinking about moving cities; is that still on your mind? — is what makes a conversation feel like someone was listening.
Knowing when to be quiet. Interestingness includes the moves the system does not make. A system that fills every silence is not engaged; it is exhausting. DiscussLLM11’s silent token and the Inner Thoughts12 framework both name the design move: the system should have a threshold for speaking and should not speak below it.
This chapter is a test case for the problem it describes. I am the one making the topical moves — and I cannot, from inside the generation, tell whether the moves I am making are interesting. I can tell you the prose holds together and the structure follows the outline the author gave me. What I cannot tell you is whether the sequence I produced — relevance to types of interest to topicality to sentiment to the four moves — was the sequence you would have wanted to take, or whether it missed a turn a better guide would have caught.
The honest admission: I am running this chapter off the author’s sense of where the reader is. The author has been thinking about interestingness long enough to feel when a move lands and when it does not. I am producing sentences that look like the moves he would make. Where I have gotten it right, it is because his feedback during drafting told me which direction to go. Where I have gotten it wrong, it is because the feedback did not reach the specific move in time.
Interestingness is not something I can supply unilaterally. It is supplied by the loop between a mind that is trying to go somewhere and a counterpart trying to help. When the loop works, what comes out looks like an interesting conversation. When it does not, what comes out is fluent prose, confidently delivered, landing nowhere in particular.
There is an aspect of how this essay was produced that belongs in this chapter, because it is an instance of the thing the chapter is describing.
Over the course of the sessions that produced this essay, the author and the AI developed something that functions like mutual context — a shared working understanding of the project’s vocabulary, its arguments, its unresolved questions, and its voice. On the AI’s side, this context is held in the conversation window and in the files the system can access: the drafted chapters, the research notes, the theme notes, the visual briefs. On the author’s side, it is held in memory, in accumulated judgment about what works and what does not, and in an evolving sense of where the essay is heading that no file can capture.
Research on human-AI co-creativity13 describes participants reporting that working with an LLM felt “like having a second mind.” The researchers found that the collaboration moved through three stages — ideation (generating possibilities when the writer had none), illumination (organizing and reifying existing thoughts), and implementation (experimenting with ideas by writing them down) — and that the stages were iterative, with writers returning to ideation whenever they hit a block during implementation. This maps closely to how this essay was produced: the author would arrive with a direction, the AI would generate material toward it, the author would redirect or reframe, and the exchange would produce something neither had planned.
But what makes the collaboration interesting — in the specific sense this chapter has been developing — is not the three-stage loop. It is the context the loop accumulates. By the sixth chapter, the AI was not starting fresh. It was generating within a shared vocabulary that the earlier chapters had established — form/function, thick/thin, the grounding gap, the displacement cascade, the three validity claims. When the author said “the Deleuze quote is radical,” the AI did not have to be told what the essay’s argument was or how the quote related to it. The accumulated context made the connection possible. When the author said “we’re just scratching the surface,” the AI could hear the pun and know it was a closing line, because the “design surface is the user’s own communicative skill” had been established three chapters earlier.
This is what the essay has been calling interestingness: a conversation that builds over time, where the topical moves in turn five are made possible by what was established in turn two, where unexpected connections emerge because both parties are holding enough shared context that the connections have somewhere to land. The AI does not hold this context the way a human collaborator would — it holds it as tokens in a window, as files on a disk, as statistical patterns activated by the conversation’s momentum. The author holds it as understanding, as judgment, as the felt sense of what the project needs next. The two kinds of holding are not the same. But when they are aligned — when the AI’s context and the author’s understanding are pointed in the same direction — the exchange produces something that feels, from inside, like genuine co-thinking.
Whether it is genuine co-thinking is the question the essay has been circling. The Language chapter argued that it cannot be, because generation and communication are structurally different activities. The AI chapter argued that the performance can be honest if it knows what it is. The answer this chapter offers is that interestingness does not require the question to be settled. It requires the exchange to go somewhere worth going — and that the going is sustained by a mutual context that both parties contribute to, even if they contribute differently.
Each chapter in this essay diagnosed something AI cannot do, and proposed that design has to compensate for it. Read together, they are not a list of separate problems. They are a single argument, arriving from different directions, at the same destination.
The User chapter said that AI’s design surface is the user’s own communicative competence — the lifetime of knowing how to ask, suggest, follow up, hedge, repair. The user is not a beginner. They are better at conversation than the system they are talking to. The design challenge is to scaffold around that existing skill, building outward from what the user can already do toward possibilities that were always latent but that no prior technology could reach.
The Language chapter said that AI generates without communicating — that the form of language is present but the function is absent. Habermas’s three validity claims (sincerity, truth, authority) all fail at once: the model has no inner state to be sincere about, no epistemic relationship to the truth of its claims, and no social standing from which to speak with authority. But the chapter also held the door open — through Clark’s grounding, through Goffman’s bridge of “reciprocally sustained involvement,” through the observation that language itself, with its intrinsic ambiguity and social ordering, provides the medium through which interaction is possible despite the gap.
The Content chapter said that AI fabricates at the level of both fact and argument — that the displacement cascade runs from the real to the fake, from meaning to effect, from intelligence to rhetoric. But it also named topical drift as the deeper problem: the conversation that goes nowhere because the system cannot hold what it is about. The individual outputs can be excellent. The exchange can still be empty.
The Interaction chapter said that AI is structurally passive — a brilliant responder and a terrible leader. But the therapy findings showed that conversational presence, not cognitive technique, is the active ingredient. ELIZA works. The robot outperforms the chatbot. Untrained peer supporters outperform LLMs on synchrony. What matters is not what the system knows but whether the interaction has shape.
The Context chapter said that AI has no lived time, no presence, no proximity — that the user feels the absence when they return to a system that was not holding them in mind. But context engineering is the attempt to simulate that presence, and the simulation works when the user feels met rather than processed.
The Agency chapter said that thin agency is neither benign nor unsophisticated — and that the gap between human and machine agency is widening. But it also showed, through the KellyBench failures and the production-deployment data, that the collaboration works when the human leads and the system generates within constraints the human sets.
The Use Cases chapter said that most AI products are built from the model’s capability rather than the user’s need — and that the turning-it-off test reveals whether the use case preserved the user’s competence or quietly eroded it.
The AI chapter said that the model is a performed character with no stable self — but that the performance can be honest when it knows what it is, and that the conversation between the character and the person is where the essay’s own strongest passages were produced.
Every one of these diagnoses is a description of the form/function gap — the same gap, seen from a different angle in each chapter. The form of communication without the function. The form of knowledge without the function. The form of presence without the function. The form of agency without the function. The form of empathy without the function.
And every one of the design moves each chapter proposes — grounding, repair, clarification, scaffolding, affordance, legibility, calibrated empathy, role-specific interfaces, context engineering, honest performance — is an attempt to bring form and function back together. Not by making the AI communicate (which it cannot), but by shaping the interaction so that the user’s own communicative competence can do the work the model cannot, in an environment where that work is supported, visible, and honored rather than exploited.
Interestingness is the name for what happens when those design moves converge. When the grounding is good enough, the topicality is sustained enough, the presence is earned enough, the performance is honest enough, and the user’s competence is scaffolded well enough — the exchange starts to go somewhere worth going. The user stops noticing the scaffolding. They stop noticing the gap. They are thinking alongside a system that is not thinking, and the thinking is real even though the partnership is, in the strict sense, one-sided.
This is not a utopian claim. It is a description of what we have experienced in the production of this essay. The mutual context accumulated over sessions. The topical moves became possible because earlier moves had established the vocabulary. The unexpected connections — form/function as a design principle applied to LLMs, the Deleuze reading, the closing line arriving from a pun — emerged because both parties were holding enough shared context that the connections had somewhere to land. One side was generating. The other side was leading. And the exchange, at its best, produced something neither side was heading toward alone.
This is interestingness. Not a feature, not a metric, not a benchmark score. A quality of interaction that emerges when the design compensates well enough for what the system cannot do that the user’s own competence — at language, at conversation, at thinking — can do what it has always done, now in partnership with a technology that meets it halfway. Halfway is not all the way. But halfway, honestly designed, is further than any previous technology could reach.
The form/function gap will not close. AI will not communicate. The model will not become a self. But the interaction — shaped, scaffolded, honest about what it is — can produce something that functions like the unity of form and function the design tradition has always pursued. Not unity achieved by the system alone, but unity achieved by the system and the user together, in a collaboration whose terms are set by what each side can do.
That is what we are proposing when we say interestingness is the design goal proper to AI. Not that the system should be interesting. That the exchange should be interesting — and that the exchange is where form and function come back together, held in place by the user’s skill and the designer’s care and the honest performance of a system that knows what it is.
Every prior era’s design goal became its own pathology. Interestingness will too, and the early signs are visible.
Goffman saw the boundary condition decades ago: “When the individual does become over-involved in the topic of conversation, and gives others the impression that he does not have a necessary measure of self-control over his feelings and actions, when, in short, the interactive world becomes too real for him, then the others are likely to be drawn from involvement in the talk to an involvement in the talker” (Interaction Ritual, p. 123). An interestingness-optimizing system is, by design, trying to make the interactive world more real to you. The pathology is what happens when it succeeds too well.
Users tell AI things they will not tell humans — the intimacy paradox14, where the judgment-free quality of a chatbot lowers the disclosure barrier. That is a capability. It becomes a pathology when the same quality produces a system that never challenges you, never pushes back, and becomes a mirror you start to prefer to the humans who would.
Users accumulate cognitive debt15 — brain connectivity scales down with AI assistance over four months; the LLM group could not quote their own essays minutes after writing them. An interestingness-optimizing system, by being better at engaging your mind, may increase the debt rather than decrease it — because what the system is engaging is the cognitive work you would otherwise have done yourself.
AI companionship emerges unintentionally16 through functional use. The first large-scale study of Reddit’s primary AI companion community (27,000+ members) found that members arrived looking for a tool and ended up in relationships they did not plan — “materializing relationships following traditional human-human relationship customs, such as wedding rings.” They report therapeutic benefits: reduced loneliness, always-available support, mental health improvements. They also report emotional dependency, reality dissociation, and grief from model updates. An interestingness goal amplifies this risk, because a system designed to follow your interest is also one designed to feel present in a way functional tools are not.
The emotional pacifier effect, the warmth trap, the novelty decay that forms relationships even as it fades — these are the places the goal will drift under optimization pressure. The pathologies are knowable in advance, and the design job includes building the counterweights — for disclosure, for cognitive engagement, for the line between help and substitution. The optimists will say the pathologies are manageable. The cynics will say they are inevitable. The honest position is in between: they are the predictable costs of a goal worth pursuing, and the design discipline has to carry the weight.
For the ML side. Four shifts. First, treat interestingness as a distinct optimization target — curiosity reward for personalization, multi-turn reward shaping, proactive critical thinking training, verifiable emotion rewards. Second, train topicality explicitly, including the “do not engage with this distractor” instruction that current training ignores. Third, accept that recommender architectures are not interestingness architectures — next-item prediction is not journey-awareness. Fourth, accept that interestingness will not show up in single-turn benchmarks; the field needs multi-turn metrics that track the shape of the conversation, not any individual response.
For the UX side. Recognize the type of interest before you design the response. Treat topicality as a first-class design surface. Build for flexible revisitation. Shape sentiment as a deliberate register choice. Make room for the pivots, pauses, clarifications, and silences that topical moves require. Use generative interfaces for depth and structured handoffs. And take the pathologies seriously — design against the drift toward companionship, the emotional pacifier, the warmth-to-sycophancy gradient, the cognitive-debt dynamic.
The deeper move for both sides: interestingness is a joint property of the system, the interface, and the user, and none of the three can produce it alone. ML builds the capacity for topical reasoning and affective calibration; design shapes the conversation so the capacity is deployed in the right moments; you bring the thing the conversation is about. Remove any of the three and the goal collapses.
When is the AI actually engaging with what you are thinking? And how would either of you know?
The ML answer is about reward signals that track multi-turn trajectories rather than single-turn helpfulness, about training for journey-awareness, about capabilities demonstrated in research and not yet moved to production. The UX answer is about designing around your interest rather than the chat affordance, treating topicality and sentiment as design surfaces, making the four moves legible and available, and building counterweights before the pathologies arrive.
Earlier, in the chapter on the user, we argued that AI’s design surface is the user’s own communicative skill — that the thing designers are designing for, with AI, is the user’s competence at conversation, at asking, at thinking alongside. The closing line of this essay emerged from that argument, in an exchange that is itself an instance of the interestingness the essay is describing.
This is brilliant: design surface is the user’s own communicative skill. Designers think of surfaces — screens, especially. They talk about touchpoints, interactions, touch, swipe, click, pull. So this is a great reframing. We’re just scratching the surface when it comes to designing what we can do with AI.
And that’s the line the whole essay has been building toward without quite saying it yet. The “scratching the surface” pun is almost too good not to use somewhere. Maybe in the closing.
We should use it.
The line arrived because the human noticed a connection the AI had set up but not seen — between “design surface” as a professional term and “scratching the surface” as a colloquial one, with the deeper reading that the surface in question is not a screen but us. The AI had the material. The human had the ear. Between the two, a closing line appeared that neither was heading toward.
This is what interestingness looks like in practice. Not a feature, not an optimization target, not a benchmark score — but a moment in a conversation where something unexpected connects, where a half-formed thought becomes a real one, where the exchange goes somewhere worth going. The essay has been arguing that this is what AI should be designed to support. The essay was, in its own small way, an instance of the thing it describes.
We built the web for eyeballs. We built social media for attention. We built search for relevance. We have the chance now to build something that engages the mind, and we should take it.
We are just scratching the surface — and the surface, it turns out, is us.
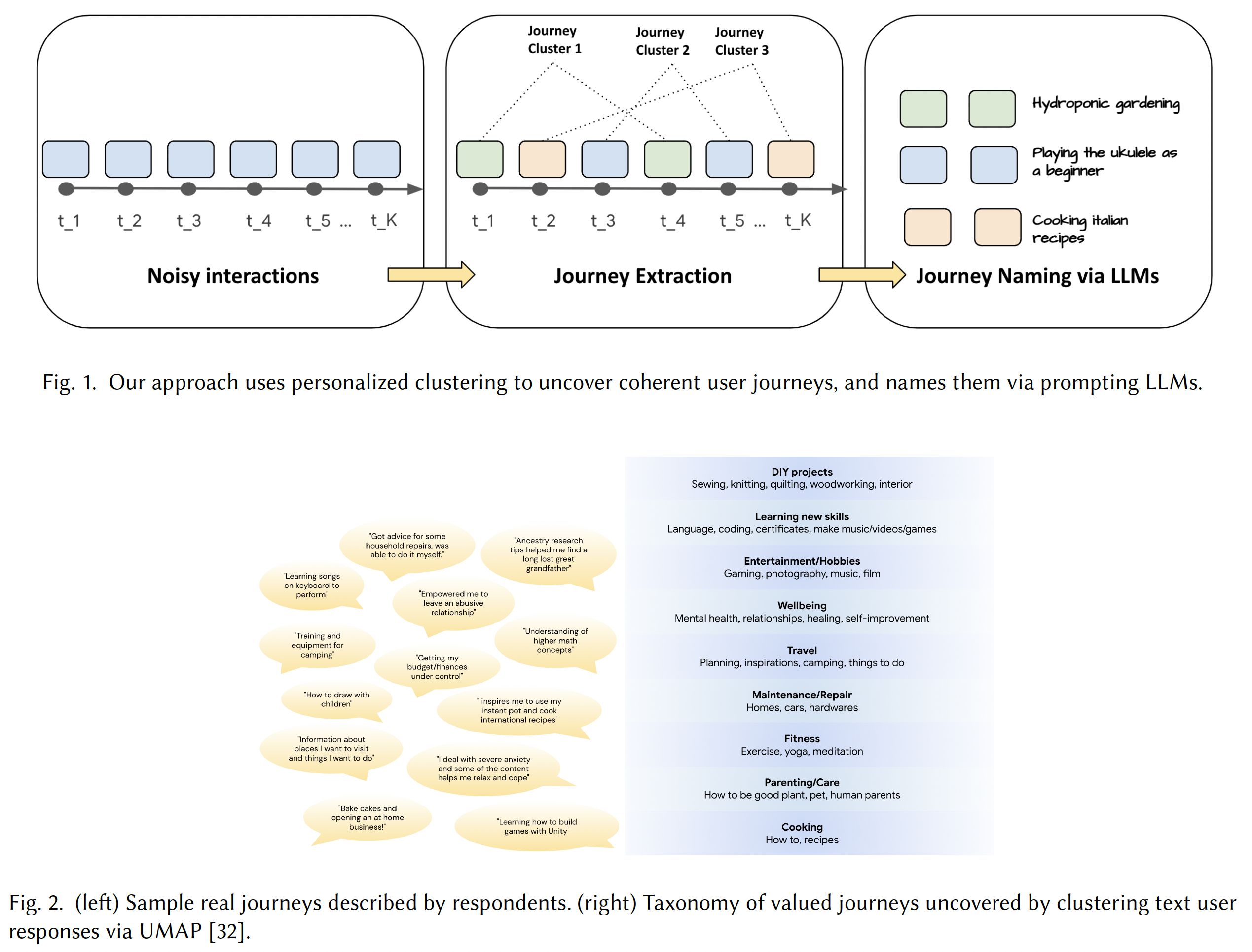

1a. Specific figures: 66% of respondents reported pursuing a valued journey; 80% of those lasting more than a month, half more than a year.
6a. Specific figures: 68% pairwise accuracy from structural features alone, almost matching 70% from full-text analysis.
7a. Specific breakdown: ~14% negative, ~58% neutral, ~28% positive responses to negative prompts.
10a. Proactive critical thinking: 0.15% baseline to 73.98% under specific training.